
UDI? UMI? 不知道区分的小伙伴赶紧进来围观!!
时间:2020-12-07 阅读:8303
| 相信有些小伙伴已经隐隐约约有听说过UDI和UMI这两个英文缩写,但是一直没搞清楚它们全名是啥?它们能干啥? |
| 在正文开始前,我们先来“揭秘”UDI和UMI的全称: UDI的全称为Unique Dual Index,译为双端标签技术。 UMI的全称为Unique Molecular Identifier,译为分子条形码或者分子标签技术。 别急,要弄清这两个概念,还得从二代测序的那些事情说起: 我们都知道二代测序技术是近十年来曝光率非常高、非常受关注的基因组分析技术。以Illumina为代表的测序仪厂商不断推出更新型号的测序仪,不断刷新测序通量,但不变的仍是多样本混合后测序的策略。 要实现对多个样本同时测序,必须在各样本PCR扩增阶段,往DNA片段上添加一段分子序列作为样本标签,这种标签叫做index。 |
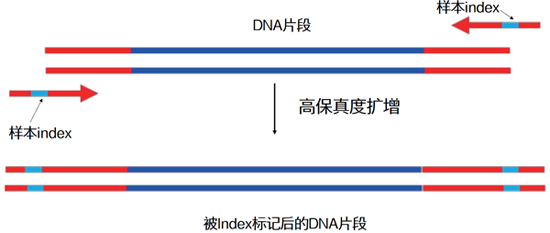 |
| 这样,每个样本就带上属于它的“专属号码牌”,在多样本混合测序后,生信工程师能通过“翻牌”,确定这个“号码”所代表的就是“寻寻觅觅”的那个“它”。 |
 |
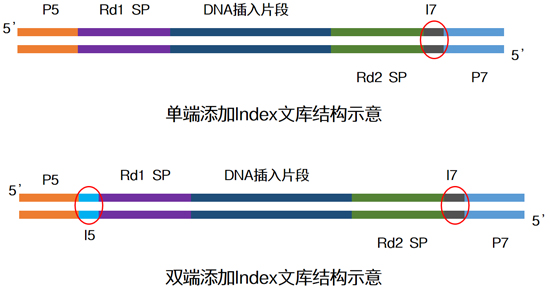
| Index一般由8位碱基所组成,常有单端与双端两种添加模式,为了增加同时上样的通量,大家一般在面临大量样本同时测序时,会选择双端index↓ |
 |
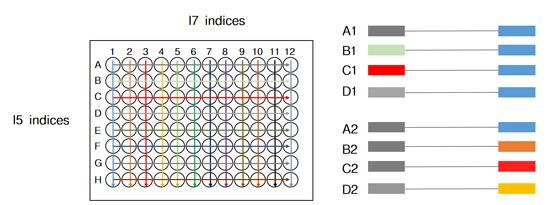
| 目前常用的双端index策略是通过少数几种index序列排列组合,去实现更多样本的标签区分(如96种),但这种方式一直存在交叉污染的可能。 |
 |
| 同时,为了进一步提升通量与扩增效率,降低测序成本,Illumina为Novaseq等高通量型测序仪引入了图案化流动槽(Patterned Flow Cell Technology,PFCT)和排他性扩增(Exclusion Amplification,ExAmp)成簇技术。这两个看似美好的技术却无意间放大了一种叫做标签跳跃(index hopping)的样本标签错配的现象,导致科研人员无法正确拆析样本与数据的关系,终可能与重大发现“失之交臂”。 |
| 为了降低标签跳跃,Illumina在白皮书[1]中提到可以使用UDI双端特殊标签对样本进行标记,混样后进行测序。 |
| UDI的引入使得文库两端的index序列是一对一组合的,不存在共用。换句话说,只有两端带有*正确index序列的reads才能进入后续的样本分析,从而可以剔除标签错配的reads,有效避免样本之间的数据串扰。 |
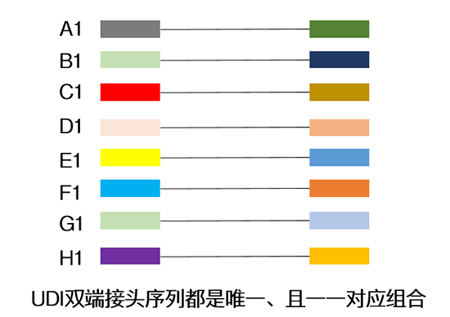 |
| 一句话总结:采用UDI策略,能更正确拆解测序数据与样本之间的一一对应关系,减小样本“戴错号码牌”的概率。 |
| 下面再来讲讲名为分子标签技术的UMI: |
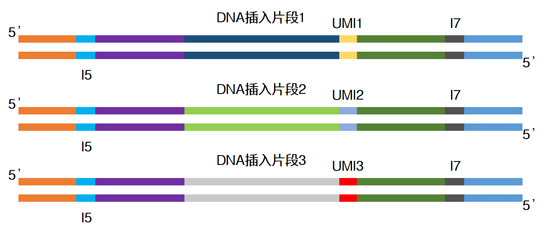
| UMI的原理就是给每一条原始DNA片段加上一段*的标签序列,经PCR扩增后一起进行测序。这样根据不同的标签序列,生信人员就能区分不同来源的DNA模板,分辨哪些是PCR扩增及测序过程中的随机错误造成的假阳性突变,哪些是患者真正携带的突变,从而提高检测灵敏度和特异性。 |
 |
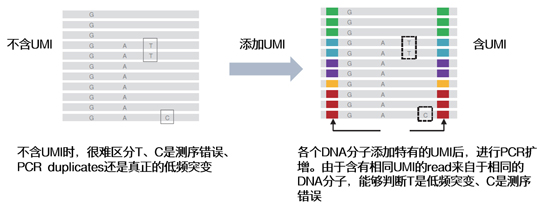 |
| 一些需要较高正确度的应用,如肿瘤稀有突变分析,常会对5%、甚至1%左右的稀有变异作检测。这时一旦出现测序错误、或者PCR偏差,便会产生大量假阳性结果,因此需要添加UMI进行校正。 |
| 一句话总结:做稀有突变检测、校正测序错误与PCR偏差,UMI“劳苦功高”。 |
| 看到这里,关于UDI和UMI的介绍已基本完成。 |
| 接下来我们来看一个实际案例应用。 |
| 我们了解到这位客户 ① 近正在研发肿瘤稀有突变分析的项目; ② 样本类型主要是FFPE(石蜡包埋样本)、cfDNA(游离DNA); ③ 起始量大概在几十ng;④准备自己建库,然后送样测序,平台是Novaseq; ⑤ 由于是刚接触建库实验,不希望操作太复杂。 我思考了大概1秒钟,就从我们丰富的DNA-Seq文库构建产品线中找到了一款合适的产品↓ |
| ThruPLEX Tag-Seq HV |
| 为什么说这款产品合适呢?我们来对标这位客户的几个需求。 |
| 需求1:希望操作简便,不要太繁琐 |
| 对标1:ThruPLEX Tag-Seq HV这款试剂盒支持单管、三步操作,手动15 min,全程2 h,无需在建库过程中转管或纯化。 |
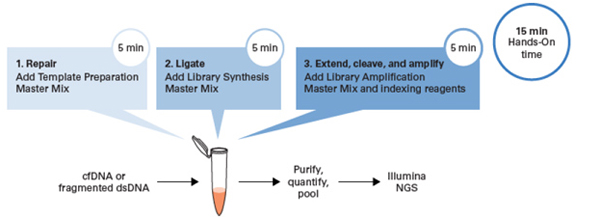 |
| 我们比较了ThruPLEX HV和K、N两家公司的试剂盒,只有ThruPLEX是单管操作、时间短的系统。 |
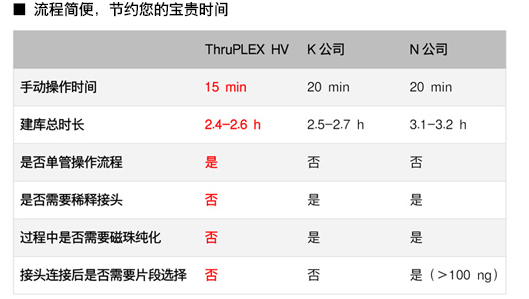 |
| 所以,无论新手还是老手,都能很快上手! |
| 需求2:样本类型为FFPE DNA、cfDNA,起始量大概在几十ng |
| 对标2:ThruPLEX Tag-Seq HV支持5-200 ng FFPE DNA、cfDNA起始,input volume为30μl,无需样品浓缩。 |
| 需求3:Novaseq测序分析稀有变异 |
| 对标3:ThruPLEX Tag-Seq HV搭配UDI建库,可以有效降低index hopping效应,是高通量型Illumina测序仪的“友好伙伴” |
| ThruPLEX Tag-Seq HV茎环形接头上还包含7位碱基的固定型UMI,双端总共可有144种UMI连接到DNA分子两端,以识别一致序列,减少扩增或者测序错误带来的假阳性突变。 |
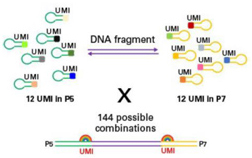 |
| 再举几个例子 |
| Takara科学家采用ThruPLEX Tag-Seq HV对10 ng起始的Quan-Plex Patient-Like ctDNA标准品(AccuRef)构建文库,肿瘤相关的基因采用IDT xGEN Pan Cancer Panel进行捕获富集,随后用UMIs鉴定了ctDNA标准品中特定位点的实际突变频率。结果显示,检测到的突变频率分别与预期1%、5%的等位突变频率接近,而阴性对照组没有在位点处检测到任何突变。 |
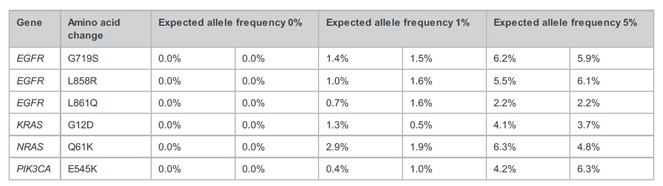 |
| 同时,为了比较UMI与常规使用的坐标法之间的效果差异,Takara科学家先使用未去重或者仅用坐标法去重的文件分析,在预期的EGFR L858R突变附近观察到大量的低频及随机等位基因频率突变。而随后用UMI校正、过滤数据后,清除了假阳性突变,得到了预期的突变分析结果! |
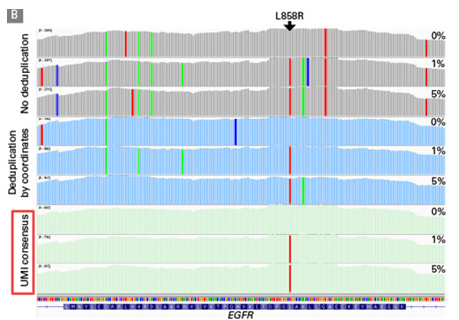 |
| 经过几场对标,我们明确了ThruPLEX Tag-Seq HV能满足那位客户开发cfDNA/FFPE DNA稀有突变项目的需求。 |
| 当然,若小伙伴们也有同等需求,ThruPLEX Tag-Seq HV定能不负所望。 |
| 参考文献: |
| [1] Illumina.Effects of index misassignment on multiplexing and downstream Analysis(white paper). 4(2017). |